本文由本人@takooctopus关于的IC学习记录
英文缩写
VLSI:very large scale integration 超大规模集成电路
STA:静态时序分析
DFT:Design for Testability 可测试设计
EDA:Design Automation 电子设计自动化
ASIC:Application Specific Integrated Circuit 专用集成电路
CPLD:Complex Programmable Logic Device 复杂可编程逻辑器件
FPGA:Field-Programmable Gate Array 现场可编程门阵列
DRC:design rules checking 设计规则检验
LVS:Layout Versus Schematic 版图与原理图一致性检查
HDL:Hardware Description Language 硬件描述语言
DCVSL:Differential Cascode Voltage Switch Logic 差分级联电压开关逻辑
RCA:Ripple-Carry Adder 行波进位加法器
CBA:carry-bypass adder 旁路进位加法器
CSA:carry-select adder 进位选择加法器
TSPC:True Single Phase Clock 真单相位时钟控制
C2MOS:主从正沿触发寄存器
简答
静态互补CMOS电路的特点(CMOS互补对称结构的特性)
- 输出摆幅等于电源电压「即高电平为VDD,低电平为GND,噪声容限大」;
- 逻辑电平与器件尺寸无关「所以晶体管可以采用最小尺寸,属于无比逻辑」;
- 稳态时,输出与VDD或者GND之间总存在一条有限的电阻通路
- 稳态时,电源和地之间没有直接的通路,没有电流存在(忽略漏电流),即无静态功耗
- 输入阻抗很高,理论上,单个反相器可以驱动无数个门
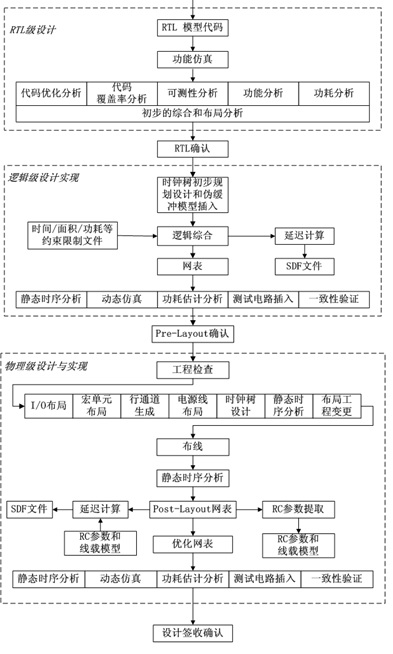
简单论述用标准单元进行超大规模集成电路设计的基本流程
RTL级设计—RTL级确认—逻辑级设计实现—Pre-layout确认—物理级设计实现—设计签收确认
证明点操作符合结合律不符合交换律
点操作:
我们首先应该定义点操作:
$$ (g,p)\cdot(i,j)=(g+ip,pj) $$
结合律:
$$ (g,p)\cdot(i,j)\cdot(x,y)=(g+ip,pj) \cdot(x,y)=(g+ip+pjx,pjy)$$
$$(g,p)\cdot [(i,j)\cdot(x,y)]= (g,p)\cdot (i+jx,jy) = (g+ip+pjx,pjy) =(g+ip+pjx,pjy) $$
交换律:
$$ (g,p)\cdot(i,j)=(g+ip,pj) $$
$$ (i,j)\cdot(g,p)=(i+gj,pj)\neq (g+ip,pj) $$
明显的,符合结合律而不符合交换律
多米诺(Domino)
原理
我们知道,简单的动态CMOS结构不能级联应用,即我们需要多米诺逻辑
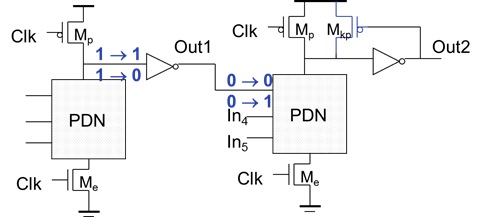
一个多米诺逻辑块由一个n型动态逻辑块后面接一个静态反向器构成「其由一个低阻抗的静态反相器驱动,提高了其的抗噪能力」
多米诺逻辑可以串联,串联的数目取决于在求值的时钟阶段,相串联的各级动态逻辑能来得及一个接一个地求值完毕
结构特点
- 逻辑求值的传播如同多米诺骨牌的倾倒,求值阶段的时间决定了逻辑深度
- 只能实现非反相逻辑(所有的门均为非反相)
- 只有一个过渡被优化
- 门为无比逻辑,但电平恢复电路为有比逻辑
- 节点必须在预充电期间被预充电「限制了PMOS的最小尺寸」
- 求值期间,输入必须稳定,对Nlogic只能有一个上升的过渡。速度非常快
- 增加电平恢复电路可以减少漏电和电荷分享问题
建立时间,维持时间,时钟偏差,时钟抖动
建立时间 $ t_{su} $:
在时钟翻转(对于正沿触发寄存器为0->1翻转)之前数据输入必须有效的时间。
维持时间 $ t_{hold} $:
在时钟边沿之后数据输入必须仍然有效的时间
传播延时 $ t_{clock-q} $:
假设建立时间和维持时间都满足要求,输入D端的数据在最坏情况下的延时「相对于时钟边沿」之后被复制到输出端Q
时钟偏差:
集成电路中一个时钟翻转的到达时间在空间上的差别通常称为时钟偏差。时钟偏差是由时钟路径的静态不匹配以及时钟在负载上的差异造成的。时钟偏差现象无论对时序系统的性能还是功能都有很大影响。正偏差能够增加电路的数据通过量,但有可能导致出错,负偏差显著提高抗竞争能力,避免出错,但会降低电路性能
时钟抖动:
时钟抖动是指在芯片的某一个给定点上的时钟发生暂时性的变化,即时钟周期在每个不同的周期上可以缩短或加长。抖动是一个平均值为零的随机变量。 $ \overset{t_{jitter}}{绝对抖动} $ 是指在某一给定位置处的一个时钟边沿相对于理想的周期性参照时钟边沿在最坏情况下的变化「绝对值」抖动直接影响时序系统的性能,最坏情况下可用来完成操作的总时间会减少 $ 2t_{jitter} $ ,降低了时序电路的性能。
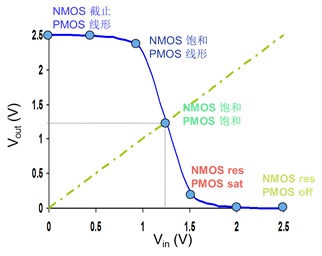
反相器的5个工作区间,并简述形成原因
如何优化设计降低大扇入组合逻辑延时
- 调整晶体管尺寸;只有当负载以扇出电容为主时,才有效果
- 逐级加大晶体管尺寸:距输出越近,晶体管尺寸越小
- 重新排晶体管的顺序,使关键路径靠近输出端
- 重构逻辑结构,变换逻辑方程的形式,降低对扇入的要求,从而减少门延时
- 在输出端和负载之间插入缓冲链
- 减小电压摆幅
动静CMOS比较
静态互补CMOS电路的特点
静态互补CMOS电路
- 全摆幅输出,即高电平为VDD,低电平为GND,噪声容限大
- 无比逻辑,逻辑电平与器件尺寸无关,所以晶体管可以采用最小尺寸
- 稳态时,输出与VDD或者GND之间总存在一条有限的电阻通路
- 稳态时,电源和地之间没有直接的通路,没有电流存在(忽略漏电流),即无静态功耗
- 输入阻抗很高,理论上,单个反相器可以驱动无数个门
动态门的特点
动态门
- 逻辑功能仅由PDN实现(紧凑),晶体管数目是N+2(静态CMOS需2N个晶体管),输入电容与伪NMOS逻辑相同, 噪声容限小,对噪声敏感
- 全摆幅输出(VOL = GND 及VOH = VDD)
- 无比逻辑–器件尺寸不影响逻辑电平
- 上拉速度改善,下拉时间变慢,快速的开关速度
- 输入只在预充电阶段允许变化,在求值阶段必须保持稳定
- 简单的动态CMOS 逻辑级不能串联
- 需要预充电/求值时钟
- 总功耗高于静态CMOS
- 对漏电敏感,有电荷泄露、电荷分享问题
动态设计信号完整性问题有哪些?怎么优化?
电荷泄露:
一个动态门的工作取决于输出值在电容上的动态存储。如果下拉网络关断,那么理想情况下,输出在求值阶段应当维持在预充电状态的VDD。然而由于存在漏电电流,这一电荷将逐渐泄露掉,最终会使这个门的工作出错。
漏电流来源主要是亚阈值导电和反偏二极管。
解决方法:增加一个泄露晶体管补偿漏电。
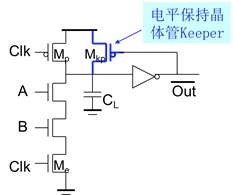
电荷分享:
原先存放在CL 上的电荷由CL 和CA 重新分布(分享),导致输出电压有所下降,鲁棒性降低。
解决办法:采用时钟驱动的晶体管预充电内部关键节点,代价是增加了面积和功耗。
-
回栅耦合(电容耦合) -
时钟馈通
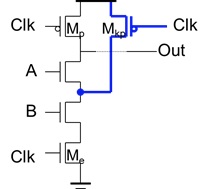
简述主从边沿触发寄存器原理
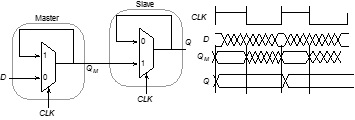
时钟为高电平时,主Latch 维持,$ Q_M $ 值保持不变,输出值 $ Q $ 等于时钟上升沿前的输入D 的值,效果等同于“正沿触发”
效果等同于“负沿触发”的主从寄存器只需互换正Latch和负Latch的位置
画出动态传输门边沿触发器结构示意图,并讨论时钟重叠问题对其时序性能的影响和解决方案
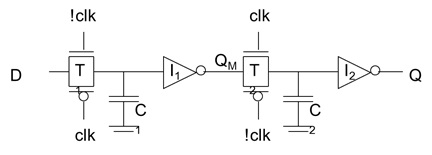
动态传输门边沿触发寄存器:只需8个晶体管,节省功耗和提高性能,甚至可只用NMOS实现。
动态时序逻辑电路特点
动态时序逻辑电路:
- 比静态Latch和Register简单
- 基于在寄生电容上存储电荷,由于漏电需要周期刷新「或经常更新数据」
- "不破坏地"读信息:因此需要输入高阻抗的器件
动态Register的时钟重叠问题
动态Register的时钟重叠问题:
在0-0重叠期间,T1的PMOS和T2的PMOS同时导通,形成数据从寄存器的D输入留到Q输出的直接通路,对于1-1重叠亦是如此。
通过强加维持时间约束来解决
- 0-0重叠竞争限制条件: $ t_{overlap0-0} < t_{T1} + t_{I1} + t_{T2} $
- 1-1重叠竞争限制条件: $ t_{overlap1-1} < t_{hold} $
数字电路时序系统分类以及各自特点
在数字系统中,信号可以根据他们与本地时钟的关系来分类。只有在预先决定的时间周期上发生翻转的信号相对于系统时钟可分为同步的、中等同步的或近似同步的。反之,可以在任意时间发生翻转的信号成为异步信号。
- 一个同步信号具有与本地时钟完全相同的频率并与该时钟保持一个已知的固定相位差。
- 中等同步信号不仅与本地时钟具有同样的频率,而且相对于该时钟具有未知的相位差。
- 一个近似同步信号是一个频率与本地时钟频率名义上相同但其真正频率却稍有不同的信号。
- 异步信号可以在任何时候随意变化,并且他们不服从任何本地时钟。
CMOS电路功耗包括哪几个?有哪些优化方法?
- 静态功耗:由泄漏电流引起
- 优化:发明能生产具有迅速彻底关断特性的器件的工艺
- 动态功耗:由充放电电容引起、由直接通路电流引起
- 优化:减小电源电压、减小等效电容(两个方面:减少实际电容、减小翻转活动性)
Wallace树乘法器原理
Wallace树充分利用全加器3-2压缩的特性,将可利用的所有输入和中间结果及时并行计算,大大节省了计算延时。其结构的关键特性在于利用不规则的树形结构对所有的准备好输入数据的运算及时并行处理。
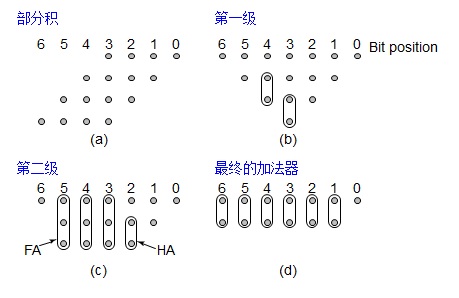
曼彻斯特进位链工作原理
曼彻斯特进位链加法器用串联的传输管实现进位链
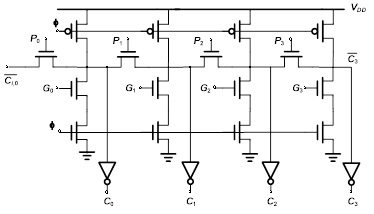
在预充电阶段,$ \Phi = 0 $ ,传输管进位链中的所有中间节点都被预充电至 $V_{DD} $ 。在求值阶段,当有输入进位且传播信号 $ P_k $ 为高电平时,或者当第k级的进位产生信号 $ G_k $ 为高电平时,节点 $ C_k $ 放电。
曼彻斯特动态进位链特点:
- 采用动态逻辑降低复杂性和加快速度
- 预充电时所有中间节点被预充至VDD ,求值时有条件放电。
- 进位链传输管只用N 管,节点电容很小,为四个扩散电容。
- 进位链的分布RC 本质使传播延时与位数N 的平方成正比,因此有必要插入缓冲器。
- 从输出端到输入端通过进位链管子的放电电流逐步加大,因此从输出端到输入端逐步加大进位链管子的尺寸可提高速度。
CBA(旁路进位加法器)、CSA(进位选择加法器)原理
CBA:
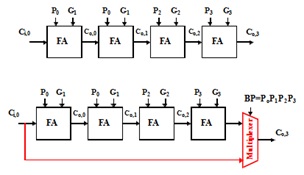
如果(P0 、P1 、P2 和P3 均= 1) 则CO,3 = Ci,0 ,否则主路径进位消除或进位产生
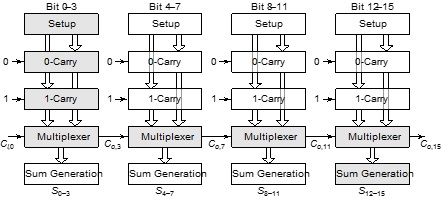
CSA:
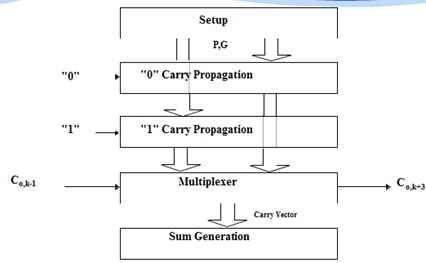
预先考虑进位输入的两种可能的值,并提前计算出针对这两种可能性的结果,一旦输入进位的确切值已知,正确的结果就可以通过一个简单的多路开关级很容易地选出
线性CSA:
关键路径以灰色显示
锁存器流水线结构?解释用剩时间借用原理?
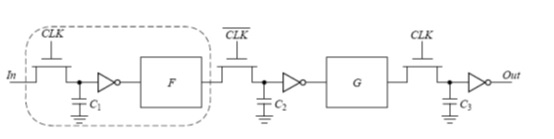
在锁存式系统中,一个逻辑块可以利用上一个逻辑快没有用完的时间。这一现象是由于锁存器在其导通期间是透明的,称之为用剩时间借用。
进位保留乘法器工作原理和延时优化?
在阵列乘法器中嫁娶一个额外的加法器来产生最终的结果,由此所得的乘法器成为进位保留乘法器,因为进位为并不立即相加,而是保留给下一级加法器。
延时优化方法:将波兹编码与4-2压缩器形成的Wallace树结合并采用传输管实现,最终的进位采用进位选择和超前进位的混合结构。
半定制集成电路与全定制集成电路对比?
全定制集成电路(Full-Custom Design Approach):
在晶体管的层次上进行每个单元的性能、面积的优化设计,每个晶体管的布局/布线均由人工设计,并需要人工生成所有层次的掩膜(一般为13层掩膜版图)。
- 优点:
- 所设计电路的集成度最高
- 产品批量生产时单片IC价格最低
- 可以用于模拟集成电路的设计与生产
- 缺点:
- 设计复杂度高/设计周期长
- NRE费用高(Non-Recurring Engineering )
- 应用范围:
- 集成度极高且具有规则结构的IC(如各种类型的存储器芯片)
- 对性能价格比要求高且产量大的芯片(如CPU、通信IC等)
- 模拟IC/数模混合IC
半定制集成电路(Semi-Custom Design Approach):
即设计者在厂家提供的半成品基础上继续完成最终的设计,只需要生成诸如金属布线层等几个特定层次的掩膜。根据采用不同的半成品类型,半定制集成电路包括门阵列、门海和标准单元等。